Keywordsbuying behavior Latent Dirichlet Allocation LDA mobile applications motivation perceived value technology acceptance model unsupervised machine learning
JEL Classification D83, C60, C80
Full Article
1. Introduction
Mobile applications (or apps) are software packages developed specifically for smart phones or tablets. A recent study (Annual number of mobile app downloads worldwide 2022 | Statistic, 2018) shows an increasing number of mobile applications downloads, estimated at 205.4 billion in 2018 and forecasted at 258.2 in 2022. As of 2018, another study provided by Statista (App stores: number of apps in leading app stores 2018, 2018) estimates that the distribution is dominated by the platform providers, Google (with 2.1 Million apps) and Apple (2M apps) followed by Microsoft and Amazon ( under 700K applications available each).
With the growing number of application, users face a significant challenge in identifying relevant or useful applications to fit their needs. It is general accepted that recommendations, ratings or user reviews increases the acceptance of applications and helps user to choose (Sun et al., 2017) and deals with user experience or functionality. Personality traits (Lane and Manner, 2011) were considered as variables, analyzing the effect of “Big Five” traits in choosing specific applications, while another study (Tan and Yang, 2014) concluded that extroversion will positively influence the usage of specific categories.
It is known that many developers offer with zero cost version limited functionality, trial or advertisement in the app. The user can opt for conversion into a full app, especially for content providers (Hsu and Lin, 2015). They found that value-for–money is a strong influencer of the intention to purchase from the perspective of Perceived Value in a study that explored different motivational categories for apps with limited functionality in TAM context. Other influencers are free alternatives or app ratings.
Other studies used survey, interview or user generated free text format data to capture the needs that mobile apps are satisfying (Wang et al., 2013; Guerreiro, Rita and Trigueiros, 2016; Raphaeli, Goldstein and Fink, 2017; Jelodar et al., 2017; D’Avanzo and Pilato, 2015; Vu et al., 2015; Bonds-raacke and Raacke, n.d.; Pang and Lee, 2006; Kang and Park, 2014; Jr, n.d.; Lee et al., 2011). Some studies evaluated automation in classifying new comments (Platzer, 2018) or provide sentiment analysis (Athanasiou and Maragoudakis, 2017; Kang and Park, 2014; Ortigosa, Martín and Carro, 2014).
The current research used natural language processing to infer potential categories of motivation/ users by identifying the key terms extracted from their free text survey input using Gensim (Rehurek and Sojka, 2010) as an interface to Latent Dirichlet Analysis (known as LDA) algorithm in Python and a set of libraries as NLTK (Bird, Klein and Loper, 2009).
2. Literature Review
Adoption of technology is a well researched domain, but the current paper focuses on Technology Acceptance Model (or abbreviated in this paper as TAM) (Davis, 1986; Davis, Bagozzi and Warshaw, 1989b; Davis, 1993). While the initial model of TAM developed overtime and is used frequently to describe technology adoption or continuation of use (Venkatesh and Bala, 2008; Venkatesh, 2003; Lee, Kozar and Larsen, 2003a; Hwang, Al-Arabiat and Shin, 2015) in this case the initial model was used due to generalization capability.
TAM represented a development of Theory of Reasoned Action (TRA) (Ajzen and Fishbein, 1980) a model that tried to predict attitudinal and behavioral intention, with a research focus on attitude. In this respect, the Technology Acceptance Model (TAM) is based on well-established theories about general consumer behavior, Theory of Reasoned Action (TRA) and Theory of Planned Behavior (TPB) (Lee, Kozar and Larsen, 2003). It was regarded both as practical in explaining the IT adoption and use of technology (Wixom and Todd, 2005), or how users perception (Davis, Bagozzi and Warshaw, 1989a) and attitude (Venkatesh and Davis, 2000) influences behavioral intention and atitude towards using it, but also encountered criticisms due to limited guidance to practitioners (Lee, Kozar and Larsen, 2003) in a study that describes TAM evolution from its appearance in 1986 to model extensions or elaborations.
TAM is based on two main constructs, Perceived Usefullnes (PU or U) and Perceived Easy of Use (PEOU or E) describing how the perceived value in an event driven model could activate the Behavioral intention to use (BI) - that indicates the level of individual's readiness to perform a given behavior, assumed to be an immediate antecedent of behavior (Ajzen et al., 2002).
External variables also include all the system design features. Attitude Toward Using construct is mediated by Behavioral Intention to use (BI) and has an indirect positive influence effect to the actual system use (Davis, 1993).
While motivation construct is not included in original model, it is mapped by External Variables construct. A potential motivation model could be intrinsic and extrinsic motivation (Deci, 1972) that claims that a person will have different behaviors based on the source of motivational factors, internally driven motives compared to motivation factors that comes externally as rewards or punishments .
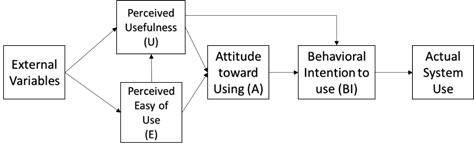
Figure 1. TAM Model Version 1, adapted (Davis, Bagozzi and Warshaw, 1989a)
Motivational research is very broad and many papers presents aggregated views and historical evolution of various theories ( Sekhar, Patwardhan and Singh, 2013; A et al., 1995; Tinne, 2010) as well as their origin. In the context of mobile and internet use, exists a significant number of papers researching the impact of motivational construct in either adoption or continuation of use (Ono et al., 2012; McLean, 2018) trying to either classify it as utilitarian, impulsive, hedonic, monetary (Muruganantham and Bhakat, 2013; Kukar-Kinney, Scheinbaum and Schaefers, 2016; Ono et al., 2012; Hsiao, Chang and Tang, 2016; Arnold and Reynolds, 2003; Totawar and Nambudiri, 2014), but there is a lack of unified terminology or approaches. Researchers evaluated creation of reference models from exiting literature (Chang, Cheung and Lai, 2005) that presents in a very comprehensive way a large number of constructs (like service quality, overall trust, beliefs, relative advantage, shopping experience) and control variables (as gender, income, age) and their dynamics from multiple perspectives (web as a channel, product characteristics, consumer characteristics), creating a summarization table of direct or indirect effects, direction and the supporting research studies. While impressive, the study does not include explicit motivational constructs.
Other studies investigated directly the m-commerce adoption, trying to predict channels usage (Chong, 2013a) or the role of motivation, gender and demographics (Chong, 2013b; Faqih and Jaradat, 2015; Ramirez-Correa, Rondan-Cataluña and Arenas-Gaitán, 2015; Natarajan, Balasubramanian and Kasilingam, 2017). Findings from Chong (2013) were challenged indicating that chronological age does not represent a strong control variable but rather a mediator and potential bias introduced by the scale used from a floor and ceiling effect (Kuppelwieser, Sarstedt and Tuzovic, 2014).
Psychological needs captured by Maslow (1943) are useful in e-commerce or m-commerce analysis (Sengupta, 2011; Stotz and Bolger, 2011) and could be used to model categories of motivation. The motivational categories included in this research are Communication Motivation (Kang, 2014; Kang and Park, 2014; Park, 2010; Park, Lee and Cheong, 2008; Kim, Kim and Park, 2010), Social Utility Motivation and Enjoyment Motivation (Kang, 2014; Kim, Kim and Park, 2010; Chang, Cheung and Lai, 2005) while other candidates categories include: utilitarian, low-cost, security, health, hedonic, social, cognitive, and self-actualization needs (Sun et al., 2017). However the interactions between these categories are not covered in this study.
Opinions or feedback is captured often using free text format. Natural Language Processing (NLP) can be applied to opinion mining or sentiment analysis and automatic computer software can perform classification of new text passages or extraction of similarities from exiting corpus, generating hidden or valuable information (Liu, n.d.; Chen et al., 2014; Clark, Fox and Lappin, 2010; Bird, Klein and Loper, 2009). Other researchers used NLP to improve the customer experience with recommender systems (Lü et al., 2012; Chen, Chen and Wang, 2015) or discover new topics about their products (McAuley and Leskovec, 2013; Villarroel et al., 2016) or users (Unal, Temizel and Eren, 2017). Computer based topic modeling is alternative to human labeling. The current paper considers Latent Dirichlet Analysis (LDA) (Barde and Bainwad, 2018; Blei, Ng and Jordan, 2003) being an option for unsupervised learning from an existing corpus of text (Jelodar et al., 2017; Nabli, Ben Djemaa and Ben Amor, 2018), with Gensim providing a practical interface for LDA algorithm implementation (Rehurek and Sojka, 2010). LDA provides a “bag of word model ”, unsupervised learning, where order is not important for analysis and no manual work is needed for data labeling. That make it useful in analyzing large, unstructured sources of data in plain text format (Jelodar et al., 2017; Alghamdi and Alfalqi, 2015). LDA is based on statistical (Bayesian) topic models and is a generative model that can be used for document generation on a specific topic.
LDA includes some concepts as documents, topics and fixed vocabulary. Documents can be described by its specific (probabilistic sampling) distribution of words from a fixed dictionary and can contain multiple topics. LDA output includes two indicators: affinity score – belongingness to a specific topic of the document, expressed as probability and the probability of a word belonging to a specific topic (Hagen, 2018).
For the current research LDA is used to extract potential clusters/ topics from corpus and investigate if they can be mapped to some motivational categories.
Corpus preparation and cleaning was done using a series of packages running on top of Python as NLTK – Natural Language Toolkit (Bird, Klein and Loper, 2009) that provides stemming (extraction of the root of the word using wordnet stemmer) and stop words removal with stopwords corpus (removal necessary due to their high frequency) (Bird and Loper, 2004). Tokenization was done with the embedded Regextokenizer class in NLTK. Other data cleaning included lower case transformation and punctuation removal.
3. Research Objectives and Methodology
Philosophy of Research: This research accepts a constructivist approach, without a specific dogmatism, with a general epistemological direction, positivist explanatory for the performed quantitative research (Catoiu, Balan and Orzan, 2009). The study aims to answer the following research question:
- Can opinions related to willingness and motivation to pay for mobile applications be used to identify different topics and describe Perceived Usefulness factors?
Research Methodology: Qualitative and quantitative methods were used (Catoiu, Balan and Orzan, 2009; Patten, 2007; Catoiu and Teodorescu, 2004) covering:
- Research design and target population: This research aims to identify topics from user opinions captured with a survey instrument as part of a larger study. Target population in the study is adult mobile users. Note: Due to research cost and time limitations, the current study covers “White collars” (Prinz, 2015) mobile apps users without limit to a specific geographical area, that graduated university or college and are employed, their job requesting exposure to Information Technology and mobile applications. We could expect a different adoption and analysis for “Blue collars” workers (Baik et al., 2016; Kim et al., 2017) and research can be extended to this category also in the future.
- Qualitative research with semi structured interviews technique was performed, participating 10 “white collars“ users (data collection, quantitative analysis, findings report). The techniques used (Saunders, Lewis and Thornhill, 2008) included: Individual in-depth interviews (Catoiu, Balan and Orzan, 2009) with duration between 30 minutes to 1 hour, conducted in English or Romanian.
- Survey design included a number questions for control variables as gender, age and country, with a representation of 32.41% Female and 67.59 Male.
- Due to cost and accessibility limitations the largest participation was recorded for Romania 67.04%, followed by United States 2.77%, Poland 2.49% and UK 2.49% with respondents from 35 countries.
- The data collection was one using online survey instrument and processed using IBM SPSS Statistics Software. The survey instrument used Likert scale of 7 points, open-ended and single choice questions, deployed on self managed LimeSurvey Instance (Limesurvey GmbH, 2018). All survey activities were conducted in English language.
The following research hypothesis were formulated:
- H1: Opinions collected contains one or more topics. Hypothesis is derived from exiting literature specific to LDA and content mining (Alghamdi and Alfalqi, 2015; Sun et al., 2017; Hagen, 2018; McAuley and Leskovec, 2013; Liu, 2012)
- H2: The identified topics can map to motivational categories identified in literature using relevant keywords. Hypothesis is derived from LDA, where topic represents a meaningful construct.
- Opinions were collected using the following survey open-ended question: “Please write down the reasons why you would pay for a for mobile application and also why you would not pay for a mobile application”
4. Data Analysis
Due to the exploratory nature of the research, implementation was done using Jupyter Notebook (Perez and Granger, 2007; Thomas et al., 2016) considering easy visualization capabilities and line by line execution. All open-ended responses were extracted and exported using IBM SPSS and converted in a txt format in a Python readable format. The raw data included initial statements, a random sample being listed in Table 1:
Table 1. Interview statements
| id | Statement |
| 1 |
“I would not pay if there is a free version of using it with similar facilities“ |
| 2 |
If i dont find a free app and the benefits generated by application are greater then the price |
| 3 | I dont like to pay for applications |
| 4 |
I would pay for a mobile application that will keep all my data CONFIDENTIAL and for an application that is not intrusive to my phone doesnt request for access to my speaker camera contacts traffic etc |
| 5 |
I will not pay for applications that are intrusive and have multiple substitutes |
Source: Online survey
Cleaning the data was necessary for proper LDA analysis. Programmatic removal of punctuation removal was performed (a subset of characters used sampled here: “"!"#$%&'()*+,-./:;<=>?@[\]^_`{|}~”). Also the stop words were removed by extending the existing corpus in NLTK (Bird and Loper, 2004) with project specific words.

Figure 2. Sample from words removed from corpus and dictionary. Source: Author provided
After processing, cleansing, tokenization, stemming resulted a dictionary of 697 unique tokens, including root form of a word: “['pay'], ['inform'], [], ['devic'], ['secur'], ['top'], ['qualiti'], ['content'], ['music'], ['film'] ”. Gensim was used for exploratory LDA model and visualization was done based on saliency of terms (Chuang, Manning and Heer, 2012) that shows how relevant a word is for topic/ corpus and relevance with LDAvis (Sievert and Shirley, 2014).
Initial clustering with 10 clusters revealed slight overlapping of 8 clusters, by inter-topic distance using LDAvis interface, suggesting a reduction of clusters, as in LDA the number of topics is specified by researcher as a parameter.

Figure 3: Clusters explored from corpus and dictionary.
Source: Author generated
Using the same dictionary alternative analysis was done to identify model variants, as well as competing topic modeling algorithms as HDP (Hierarchical Dirichlet Process) that opposed to LDA, looks for optimal clustering inferring it from the data or LSI Latent Semantic Indexing (Barde and Bainwad, 2018; Alghamdi and Alfalqi, 2015) that helps reducing a large structure “bag of word” structure to lower dimensionality. HDP model shows interesting clusters/ associations but is not in the scope of current paper.
5. Results
After exploring LDA, HDB, LSI alternatives on same corpus, final model was LDA- 3 topics. A coherence model (Rehurek and Sojka, 2010) was run in Gensim for evaluating impact of number of topics over the coherence score, and 3 was considered satisfactory. For stability of results a large number of iterations was chosen, because we can expect that model will have slight variations in different training sessions.

Figure 4. Coherence score graph.
Source: Author generated
The final model and 30 most relevant terms are depicted in image below. Relevant words are presented with the stemmed instance.
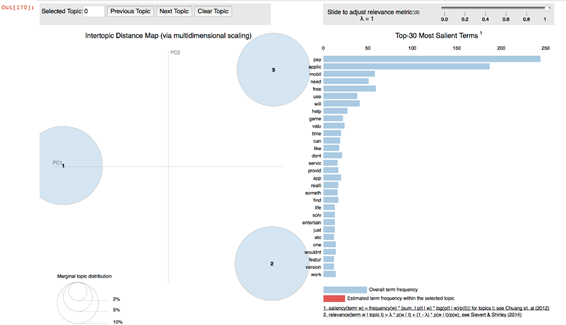
Figure 5. Final model.
Source Author generated
Topics discussions and evaluation of Hypothesis H1:
The following distribution was obtained for Cluster 1-3 (named in our array 0-2, due to Python convention)
1. Topic 1: ('0.059*"need" + 0.027*"help" + 0.024*"valu" + 0.022*"dont" + 0.020*"realli" + 0.019*"provid" + 0.018*"get" + 0.015*"servic" + 0.013*"solv" + 0.011*"etc"'),
2. Topic 2: ( '0.272*"pay" + 0.069*"free" + 0.042*"will" + 0.041*"use" + 0.023*"time" + 0.018*"like" + 0.016*"one" + 0.016*"version" + 0.014*"someth" + 0.014*"just"'),
3. Topic 3: ('0.194*"applic" + 0.066*"mobil" + 0.022*"game" + 0.021*"app" + 0.020*"can" + 0.016*"find" + 0.013*"featur" + 0.012*"ad" + 0.012*"life" + 0.011*"qualiti"')
As seen, the model generates for each term individual probability of belongingness to a specific cluster. Visualisation of topics and top 10 relevant terms helps evaluating H1. From this perspective the opinions contains three distinct topics.

Figure 6. Words relevant to each topic
Source: Author generated
It is no doubt that the exploratory analysis requires human judgement to make sense of the LDA results. Based on considerations expressed in the literature review section, we look at a series of motivational categories as:
1. Social Utility Motivation: not individually represented. For paid applications, it seems that the category of Social Utility is limited, as they provides a mobile channel for services and goods. Other words as services, provide, get or solve supports also the utilitarian category.
2. Communication Motivation: Topic 1 is a candidate for mapping. Relevant keywords suggest the utilitarian category, including need, help and value
3. Entertainment Motivation: Topic 3 is a candidate for mapping as hedonic and entertainments words have a large contribution, also the presence of both app an d application. Also suggest that user is looking for features and quality, as well as willingness to spend time for choosing a mobile app. Ad refers to mobile advertisement, that sometimes user can choose to have if not paying for full non-ads app version.
4. Low Cost / Free Motivation: Topic 2 is a candidate for this category of motivation first two relevant words being pay and free. Remaining words suggest that user will look for alternate mobile apps and not way when the need is recognized.
As a result of analysis, H1 and H2 are considered validated, within the limits of current research. Working with more topics (clusters) can bring interesting findings from the corpus but faces the challenge of coherence score getting lower.
Testing new data points against the topic model.
As cited before, LDA assumes that a document can be represented across multiple topics as probabilities. Few new sentences collected from semi-structured interviews were screened against the saved model, to evaluate how the LDA classification model performs. They represent new documents that need to be classified by the model (given the fixed vocabulary LDA uses, new words not present will not contribute to the end results).
Statement 1: ”I will pay if I see some value!” is tokenized in ” "i", "will" ,"pay", "if", "i see", "some" ,"value " ; after cleaning and processing , the model provides a 66.64 probability that statements belongs to Topic 1 (id 0 in a Python list), with almost equal distribution 16.8 for Topic 2 and 3. That confirms that willingness to pay belongs to a motivational category that looks for direct value, more utilitarian perspective, as human annotator classified in parallel.
![]()
Figure 6. Topic probability on test sentence. Topic 1 scores highest, ID is [0-2] according to Python specifications.
Statement 2: “'i pay for value of the games '” generates a classification result as following:
Result: [(Topic 1, 0.16679786), (Topic 2, 0.16679157), (Topic 3, 0.66641057)]
In that case, even if both payment and game keywords are present, the main motivator belongs to Entertainment motivation category.
It is no doubt that running individual topic scores can be obtain for each document / statement using the trained model to generate probabilities across the three categories. That could lead to a more advanced analysis using in a predictive model these inferred coefficients. Future exploration using SEM (Byrne, 2000) would require the to work with a smaller sample due to missing data, but still large enough. Also analysing the topics from gender and age perspective could bring practical findings.
The results are summarized in the following list:
a) Results indicates that based on trained LDA model from a survey based corpus on real user opinions, some motivational categories can be inferred, so this research considers H1 and H2 validated. The topics reflect motivational categories from literature.
b) The target population can highly influence the topic distribution; the results in current study are limited to “white collar workers”
c) LDA cannot reproduce exact parametric model each training session and large corpus is needed for stable results or high number of passes. Gensim provides a stable interface for analysis.
d) LDA Topic 2, Low Cost/ Free users is interestingly to study as is centric to free/paid challenge for developers (Dinsmore, Swani and Dugan, 2013)
Limitations:
- As noted, cost and accessibility limited the coverage of data collection across markets and user profiles.
- LDA is still challenged by potential changes in model parameters after retraining. The study used parameter-Passes value=300, as number of passes through the corpus during training, to ensure similar results in repeated training sessions.
- Use of stemming can help for smaller corpus and the researcher can choose to include it or not as sometimes makes results less readable.
- The analysis can be extended beyond exploratory analysis towards confirmatory analysis.
- Motivational categories identified can be analyzed in the full TAM context
- The current research didn’t provided a classifier for intention to buy / no buy a mobile application. That can be a future research area.
Scope of the research was broad. Narrowing at specific mobile application can provide much tangible result for the application target audience.
6. Discussion and Conclusion
The findings empirically validated the model hypothesis H1 and H2. TAM specific relationship should be further evaluated in a different approach, specific to latent variables measurement. The research provided validation of relevant motivational factors using unsupervised learning. The practical applicability is valuable as especially if data source comes from user generated content, while with a survey instrument the cost can limit the benefit and available data. While LDA is build for large datasets, it shows good performance on small datasets too.
There is significant difference / distance between clusters/ motivational categories and the most relevant ten words describes the clusters and links back to theory. Usage of tools as Gensim, NLTK or LDAvis Visualisation can help researchers to focus on research questions rather than algorithm implementation.
User generated data is constantly growing, users contributing intentionally with their time and effort writings reviews, opinions and comments providing valuable feedback for businesses (Decker and Trusov, 2010).
References
- Ajzen, I. and Fishbein, M., 1980. Theory Of Reasoned Action / Theory Of Planned Behavior. Social Psychology, 2007, pp.67–98.
- Ajzen, I., Fishbein, M., Atomic, I., Agency, E., Federal, T. and Commission, T., 2002. Theory of Reasoned Action / Theory of Planned Behavior. Social Psychology. pp.67–98.
- Alghamdi, R. and Alfalqi, K., 2015. A Survey of Topic Modeling in Text Mining. International Journal of Advanced Computer Science and Applications, 6(1). [online] Available at: http://thesai.org/Publications/ViewPaper?Volume=6&Issue=1&Code=ijacsa&SerialNo=21 [Accessed 11 Nov. 2018].
- Arnold, M.J. and Reynolds, K.E., 2003. Hedonic shopping motivations. Journal of Retailing, 79(2), pp.77–95.
- Athanasiou, V. and Maragoudakis, M., 2017. A Novel , Gradient Boosting Framework for Sentiment Analysis in Languages where NLP Resources Are Not Plentiful : A Case Study for Modern Greek †.
- Baik, B., Evans, J.H., Kim, K. and Yanadori, Y., 2016. White collar incentives. Accounting, Organizations and Society, 53, pp.34–49.
- Barde, B.V. and Bainwad, A.M., 2018. An overview of topic modeling methods and tools. Proceedings of the 2017 International Conference on Intelligent Computing and Control Systems, ICICCS. pp.745–750.
- Bird, S., Klein, E. and Loper, E., 2009. Natural Language Processing with Python. [online] Available at: http://www.amazon.com/dp/0596516495 [Accessed 10 Nov. 2018].
- Bird, S. and Loper, E., 2004. NLTK: The Natural Language Toolkit. In: The Companion Volume to the Proceedings of 42st Annual Meeting of the Association for Computational Linguistics. Barcelona, Spain: Association for Computational Linguistics, pp.214–217.
- Blei, D.M., Ng, A.Y. and Jordan, M.I., 2003. Latent Dirichlet Allocation. J. Mach. Learn. Res., 3, pp.993–1022.
- Bonds-raacke, J. and Raacke, J., n.d. MySpace and Facebook: Identifying Dimensions of Uses and Gratifications for Friend Networking Sites.
- Byrne, B.M., 2000. Structural Equation Modeling With AMOS. Abingdon, United Kingdom: Routledge.
- Cătoiu, I., Bălan, C. and Orzan, G., 2009. Cercetări de marketing: tratat. Bucureşti: Uranus.
- Cătoiu, I. and Teodorescu, N., 2004. Comportamentul consumatorului. Bucureşti: Editura Uranus.
- Chang, M.K., Cheung, W. and Lai, V.S., 2005. Literature derived reference models for the adoption of online shopping. Information and Management, 42(4), pp.543–559.
- Chen, L., Chen, G. and Wang, F., 2015. Recommender systems based on user reviews: the state of the art. User Modeling & User-Adapted Interaction, 25(2), pp.99–154.
- Chen, N., Lin, J., Hoi, S., Xiao, X. and Zhang, B., 2014. AR-miner: mining informative reviews for developers from mobile app marketplace. Icse, (2014), pp.767–778.
- Chong, A.Y.L., 2013a. A two-staged SEM-neural network approach for understanding and predicting the determinants of m-commerce adoption. Expert Systems with Applications, 40(4), pp.1240–1247.
- Chong, A.Y.L., 2013b. Mobile commerce usage activities: The roles of demographic and motivation variables. Technological Forecasting and Social Change, 80(7), pp.1350–1359.
- Chuang, J., Manning, C.D. and Heer, J., 2012. Termite: visualization techniques for assessing textual topic models. In: Proceedings of the International Working Conference on Advanced Visual Interfaces - AVI ’12. [online] the International Working Conference. Capri Island, Italy: ACM Press, p.74. Available at: http://dl.acm.org/citation.cfm?doid=2254556.2254572 [Accessed 2 Oct. 2018].
- Clark, A., Fox, C. and Lappin, S., 2010. The Handbook of Computational Linguistics and Natural Language Processing.
- D’Avanzo, E. and Pilato, G., 2015. Mining social network users opinions’ to aid buyers’ shopping decisions. Computers in Human Behavior, 51, pp.1284–1294.
- Davis, F.D., 1986. A technology acceptance model for empirically testing new end-user information systems: theory and results. Management Science, 25, pp.787-798.
- Davis, F.D., 1993. User Acceptance of Information Technology: System Characteristics, User Perceptions and Behavioral Impacts. International Journal of ManMachine Studies, 38(3), pp.475-487.
- Davis, F.D., Bagozzi, R. and Warshaw, P., 1989a. User acceptance of computer technology: a comparison of two theoretical models. Management Science, 35, pp.181–192.
- Davis, F.D., Bagozzi, R.P. and Warshaw, P.R., 1989b. User Acceptance of Computer Technology: A Comparison of Two Theoretical Models. Management Science, 35(8), pp.982–1003.
- Deci, E.L., 1972. Intrinsic motivation, extrinsic reinforcement, and inequity. Journal of personality and social psychology, 22(1), p.113.
- Decker, R. and Trusov, M., 2010. Estimating aggregate consumer preferences from online product reviews. International Journal of Research in Marketing, 27(4), pp.293–307.
- Dinsmore, J.B., Swani, K. and Dugan, R.G., 2013. To “ Free ” or Not to “ Free ”: Trait Predictors of Mobile App Purchasing Tendencies. (February), pp.227–244.
- Faqih, K.M.S. and Jaradat, M.-I.R.M., 2015. Assessing the moderating effect of gender differences and individualism-collectivism at individual-level on the adoption of mobile commerce technology: TAM3 perspective. Journal of Retailing and Consumer Services, 22, pp.37–52.
- Guerreiro, J., Rita, P. and Trigueiros, D., 2016. A Text Mining-Based Review of Cause-Related Marketing Literature.
- Hagen, L., 2018. Content analysis of e-petitions with topic modeling: How to train and evaluate LDA models? Information Processing & Management, 54(6), pp.1292–1307.
- Hsiao, C.-H., Chang, J.-J. and Tang, K.-Y., 2016. Exploring the influential factors in continuance usage of mobile social Apps: Satisfaction, habit, and customer value perspectives. Telematics and Informatics, 33(2), pp.342–355.
- Hsu, C.-L. and Lin, J.C.-C., 2015. What drives purchase intention for paid mobile apps? – An expectation confirmation model with perceived value. Electronic Commerce Research and Applications, 14(1), pp.46–57.
- Hwang, Y., Al-Arabiat, M. and Shin, D.-H., 2015. Understanding technology acceptance in a mandatory environment: A literature review. Information Development, 31(3), pp.1–18.
- Jelodar, H., Wang, Y., Yuan, C. and Feng, X., 2017. Latent Dirichlet Allocation (LDA) and Topic modeling: models, applications, a survey. arXiv:1711.04305 [cs]. [online] Available at: http://arxiv.org/abs/1711.04305 [Accessed 2 Oct. 2018].
- Mosley, R.C.Jr,. n.d. Social Media Analytics: Data Mining Applied to Insurance Twitter Posts. 2, p.36.
- Kang, D. and Park, Y., 2014. Review-based measurement of customer satisfaction in mobile service: Sentiment analysis and VIKOR approach. Expert Systems with Applications, 41(4 PART 1), pp.1041–1050.
- Kang, S., 2014. Factors influencing intention of mobile application use. International journal of Mobile Communications, 12(4), pp.360–379.
- Kim, J.U., Kim, W.J. and Park, S.C., 2010. Consumer perceptions on web advertisements and motivation factors to purchase in the online shopping. Computers in Human Behavior, 26(5), pp.1208–1222.
- Kim, M., Kim, J., Choi, J. and Trivedi, M., 2017. Mobile Shopping Through Applications: Understanding Application Possession and Mobile Purchase. Journal of Interactive Marketing, 39, pp.55–68.
- Kukar-Kinney, M., Scheinbaum, A.C. and Schaefers, T., 2016. Compulsive buying in online daily deal settings: An investigation of motivations and contextual elements. Journal of Business Research, 69(2), pp.691–699.
- Kuppelwieser, V.G., Sarstedt, M. and Tuzovic, S., 2014. The role of context and motivation variables in mobile commerce usage - A further perspective on Chong (2013). Technological Forecasting and Social Change, 88, pp.156–161.
- Lane, W. and Manner, C., 2011. The Impact of Personality Traits on Smartphone Ownership and Use. International Journal of Business and Social Science, 2(17), pp.22–28.
- Lee, K., Palsetia, D., Narayanan, R., Patwary, M.M.A., Agrawal, A. and Choudhary, A., 2011. Twitter trending topic classification. Proceedings - IEEE International Conference on Data Mining, ICDM, pp.251–258.
- Lee, Y., Kozar, K. and Larsen, K., 2003a. The technology acceptance model: past, present, and future. Communications of the Association for Information System, 12(50), pp.752–780.
- Limesurvey GmbH, 2018. Limesurvey GmbH. LimeSurvey: An Open Source survey tool. [online] Hamburg, Germany: LimeSurvey GmbH. Available at: http://www.limesurvey.org.
- Liu, B., 2012. Sentiment analysis and opinion mining. Synthesis Lectures on Human Language Technologies, 5(1), pp.1–184.
- Liu, B., n.d. Sentiment Analysis and Opinion Mining. p.168.
- Lü, L., Medo, M., Yeung, C.H., Zhang, Y.-C., Zhang, Z.-K. and Zhou, T., 2012. Recommender systems. Physics Reports, 519(1), pp.1–49.
- Maslow, A.H., 1943. A theory of human motivation. Psychological Review, 50(4), pp.370–396.
- McAuley, J. and Leskovec, J., 2013. Hidden factors and hidden topics: understanding rating dimensions with review text. Proceedings of the 7th ACM conference on Recommender systems - RecSys ’13, pp.165–172.
- McLean, G., 2018. Examining the determinants and outcomes of mobile app engagement - A longitudinal perspective. Computers in Human Behavior, 84, pp.392–403.
- Muruganantham, G. and Bhakat, R.S., 2013. A Review of Impulse Buying Behavior. International Journal of Marketing Studies, 5(3), pp.149–160.
- Nabli, H., Ben Djemaa, R. and Ben Amor, I.A., 2018. Efficient cloud service discovery approach based on LDA topic modeling. Journal of Systems and Software, 146, pp.233–248.
- Natarajan, T., Balasubramanian, S.A. and Kasilingam, D.L., 2017. Understanding the intention to use mobile shopping applications and its influence on price sensitivity. Journal of Retailing and Consumer Services, 37, pp.8–22.
- Ono, A., Nakamura, A., Okuno, A. and Sumikawa, M., 2012. Consumer Motivations in Browsing Online Stores with Mobile Devices. International Journal of Electronic Commerce, 16(4), pp.153–178.
- Ortigosa, A., Martín, J.M. and Carro, R.M., 2014. Sentiment analysis in Facebook and its application to e-learning. Computers in Human Behavior, 31(1), pp.527–541.
- Pang, B. and Lee, L., 2006. Opinion Mining and Sentiment Analysis. Foundations and Trends® in Information Retrieval, 1(2), 91–231. doi:10.1561/1500000001n
- Park, N., 2010. Adoption and Use of Computer-Based Voice Over Internet Protocol Phone Service: Toward an Integrated Model. Journal of Communication, 60(1), pp.40–72.
- Park, N., Lee, K.M. and Cheong, P.H., 2008. University Instructors’ Acceptance of Electronic Courseware : An Application of the Technology Acceptance Model. Journal of Computer-Mediated Communication, 13(1), pp.163–186.
- Patten, M.L., 2007. Qualitative versus Quantitative Research. Understanding research methods: an overview of the essentials, pp.21–23.
- Perez, F. and Granger, B.E., 2007. IPython: A System for Interactive Scientific Computing. Computing in Science & Engineering, 9(3), pp.21–29.
- Platzer, E., 2011. Opportunities of automated motive-based user review analysis in the context of mobile app acceptance. in Proceedings CECIIS 2011, pp.309-316.
- Prinz, M., 2015. White-Collar Workers, History of. In: J.D. Wright, ed., International Encyclopedia of the Social & Behavioral Sciences (Second Edition). [online] Oxford: Elsevier, pp.564–568. Available at: http://www.sciencedirect.com/science/article/pii/B9780080970868620238 [Accessed 11 Nov. 2018].
- Ramirez-Correa, P.E., Rondan-Cataluña, F.J. and Arenas-Gaitán, J., 2015. Predicting behavioral intention of mobile Internet usage. Telematics and Informatics, 32(4), pp.834–841.
- Raphaeli, O., Goldstein, A. and Fink, L., 2017. Analyzing online consumer behavior in mobile and PC devices: A novel web usage mining approach. Electronic Commerce Research and Applications, 26, pp.1–12.
- Rehurek, R. and Sojka, P., 2010. Software Framework for Topic Modelling with Large Corpora.
- Saunders, M., Lewis, P. and Thornhill, A., 2008. Research Methods for Business Students. Research methods for business students.
- Sekhar, C., Patwardhan, M. and Singh, R.K., 2013. A literature review on motivation. Global Business Perspectives, 1(4), pp.471–487.
- Sengupta, S.S., 2011. Growth in Human Motivation : Beyond Maslow. Indian Journal of Industrial Relations, 47(1), pp.102–116.
- Sievert, C. and Shirley, K., 2014. LDAvis: A method for visualizing and interpreting topics. In: Proceedings of the Workshop on Interactive Language Learning, Visualization, and Interfaces. Maryland, USA: Association for Computational Linguistics, pp.63–70. [online] Available at: http://aclweb.org/anthology/W14-3110 [Accessed 2 Oct. 2018].
- Statista, 2018. Annual number of mobile app downloads worldwide 2022 | Statistic. [online] Statista. Available at:https://www.statista.com/statistics/271644/worldwide-free-and-paid-mobile-app-store-downloads/ [Accessed 10 Nov. 2018].
- Statista, 2018. App stores: number of apps in leading app stores 2018. [online] Statista. Available at: https://www.statista.com/statistics/276623/number-of-apps-available-in-leading-app-stores/ [Accessed 10 Nov. 2018].
- Stotz, B.R. and Bolger, B., 2011. Content and Process Theories of Motivation. pp.16–27. Oxford: The Incentive Marketing Association.
- Sun, Z., Ji, Z., Zhang, P., Chen, C., Qian, X., Du, X. and Wan, Q., 2017. Automatic labeling of mobile apps by the type of psychological needs they satisfy. Telematics and Informatics, 34(5), pp.767–778.
- Tan, W.-K. and Yang, C.-Y., 2014. Internet Applications Use and Personality. Telemat. Inf., 31(1), pp.27–38.
- Thomas, K., Benjamin, R.-K., Fernando, P., Brian, G., Matthias, B., Jonathan, F., Kyle, K., Jessica, H., Jason, G., Sylvain, C., Paul, I., Damian, A., Safia, A., Carol, W. and Team, J.D., 2016. Jupyter Notebooks – a publishing format for reproducible computational workflows. Stand Alone, pp.87–90.
- Tinne, W.S., 2010. Impulse purchasing : A literature overview. ASA University Review, 4(2), pp.65–73.
- Totawar, A.K. and Nambudiri, R., 2014. Mood and Self-Efficacy: The Moderation of Hedonic and Utilitarian Motivation. Human Resource Development Review, 13(3), pp.314–335.
- Unal, P., Temizel, T.T. and Eren, P.E., 2017. What installed mobile applications tell about their owners and how they affect users’ download behavior. Telematics and Informatics, 34(7), pp.1153–1165.
- Villarroel, L., Bavota, G., Russo, B., Oliveto, R. and Di Penta, M., 2016. Release planning of mobile apps based on user reviews. Icse, (June), pp.14–24.
- Velayutham, C.M. and Phil, M., 1995. Consumer Buying Behaviour – A Literature Review. pp.8–16.
- Venkatesh, V., 2003. User Acceptance of Information Technology: Toward a Unified View. MIS Qarterly, 27(3), pp.425–478.
- Venkatesh, V. and Bala, H., 2008. Technology acceptance model 3 and a research agenda on interventions. Decision Sciences, 39(2), pp.273–315.
- Venkatesh, V. and Davis, 2000. A Theoretical Extension of the Technology Acceptance Model: Four Longitudinal Field Studies. Management Science, 46(2), pp.186–204.
- Vu, P.M., Nguyen, T.T., Pham, H.V. and Nguyen, T.T., 2015. Mining User Opinions in Mobile App Reviews: A Keyword-based Approach. [online] Available at: http://arxiv.org/abs/1505.04657.
- Wang, H., Nie, X., Liu, L. and Lu, J., 2013. A fuzzy domain sentiment ontology based opinion mining approach for Chinese online product reviews. Journal of Computers (Finland), 8(9), pp.2225–2231.
- Wixom, B.H. and Todd, P.A., 2005. A theoretical integration of user satisfaction and technology acceptance. Information Systems Research, 16(1), pp.85–102.
Article Rights and License
© 2018 The Author. Published by Sprint Investify. ISSN 2359-7712. This article is licensed under a Creative Commons Attribution 4.0 International License.
